L'évaluation
-
La précision: utilisation de la courbe ROC ou de l'indice de Gini pour évaluer la précision
-
La robustesse : le modèle doit dépendre le moins possible de l'échantillon d'apprentissage utilisé, varier peu en cas de valeurs manquantes...
-
La concision : ou parcimonie : modèle le plus simple s'appuyant sur le moins de choses possibles
-
Des résultats explicites : pouvoir interpréter le résultat
-
La diversité des types de données manipulées : possibilité de traiter des données discrètes ou manquantes
-
La rapidité de calcul du modèle : possibilité de mieux régler le modèle
-
Les possibilité de paramètrage : pondération des erreurs par exemple
La généralisation, c'est la capacité d'un modèle à être efficace sur des données qui n'ont pas servi à sa conception.
On distingue en général trois groupes de données :
-
les données d'apprentissage : servent à calculer le modèle
-
les données de validation : servent à vérifier la généralisation du modèle pour les paramètres courants
-
les données de test : ne sont utilisées qu'une fois les paramètres définitivement fixés (équivalent des données d'application).
Toute donnée utilisée une fois en test ne devrait jamais resservir dans ce groupe : elle devient automatiquement une donnée de validation. Il est conseillé d'isoler physiquement les données de test tout au long de la conception ou d'une étude de data-mining pour ne pas risquer une utilisation malencontreuse, qui fausserait l'évaluation de la capacité réelle de généralisation.
Peut être due :
-
Si le taux d'erreur sur les données d'apprentissage est faible ou nul :
-
-
à un nombre insuffisant de données d'apprentissage : les données ne sont pas représentatives du problème à traiter
-
au sur-apprentissage : le modèle apprend par-coeur les données d'apprentissage sans parvenir à en tirer de l'information (il faut alors changer le réglage du modèle). Exemple simple de sur-apprentissage : l'interpolation exacte par polynôme de Lagrange...
-
-
Si le taux d'erreur sur les données est plutôt élevé
-
-
à un mauvais réglage des paramètres
-
à un mauvais choix de représentation des données
-
à l'absence de l'information recherchée dans les données
-
L'ensemble de validation sert à évaluer la performance probable d'un modèle.

Le choix des données de l'ensemble de validation est critique : si cet ensemble n'est pas représentatif, alors le modèle choisi risque de ne pas bien généraliser. D'une certaine façon, on risque de sur-apprendre l'ensemble de validation.

Effets de la validation croisée
-
Le moyennage de l'erreur en validation sur différents groupes de données permets de limiter l'impact de données non représentative.
-
La méthode convient lorsqu'il y a peu de données, car toutes servent à la fois à apprendre et à valider
-
La méthode du Leave-One-Out pousse le concept à l'extrême en posant
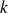 = nombre d'exemples disponibles. Très utile pour les bases d'apprentissage vraiment petites.
= nombre d'exemples disponibles. Très utile pour les bases d'apprentissage vraiment petites. -
Méthode gourmande en temps!
-
la matrice de confusion
-
la courbe ROC
La matrice de confusion permet de mesurer le taux d'erreur (ou taux de mauvais classement) par classe.
|
Prédit / Réalisé |
Classe 1 |
Classe 2 |
|---|---|---|
|
Classe 1 |
300 |
2 |
|
Classe 2 |
40 |
250 |
La matrice de confusion permet de facilement visualiser quelles classes sont bien apprises et lesquelles posent plus de problèmes.
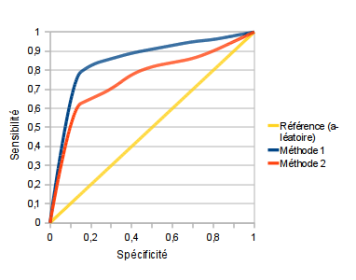
La courbe ROC (Receiver Operating Characteritics) est une technique issue du traitement du signal. Elle représente la proportion d'événements (classe
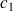 prédits
) détectés comme tels en fonction de la proportion de faux événements (classe
prédits
) détectés comme tels en fonction de la proportion de faux événements (classe
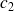 prédits
). Les détections se font en fonction d'un seuil
prédits
). Les détections se font en fonction d'un seuil
 que l'on fait varier.
que l'on fait varier.
Plus précisément, on définit deux fonctions de
-
la sensibilité
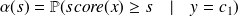
-
la spécificité
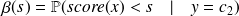
et l'on peut dire que la proportion de faux événements parmi les non-événements est
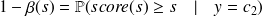
La courbe ROC représente donc
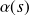 en fonction de
en fonction de
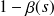 pour des valeurs de
allant du maximum (on considère tous les individus comme des non-événement, d'où
pour des valeurs de
allant du maximum (on considère tous les individus comme des non-événement, d'où
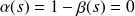 ) au minimum (on considère tous les individus comme événement, d'où
) au minimum (on considère tous les individus comme événement, d'où
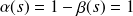 .
.
Le calcul de la courbe ROC se sert de la matrice de confusion à chaque valeur du seuil. On peut facilement calculer la sensibilité et la spécificité à partir de la matrice de confusion :
|
P/R |
oui |
non |
|
oui |
|
|
|
non |
|
|
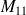
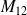
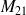
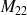
On a
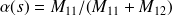 et
et
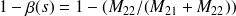 .
.
La courbe ROC permet :
-
De comparer des modèles différents avec un critère neutre
-
De comparer les comportements globaux et locaux des méthodes : une méthode peut-être globalement moins bonne mais localement meilleure (et vice-versa).
L'aire sous la courbe (AUC : Air Under Curve) permet de comparer les modèles avec une seule valeur. Un AUC de 0.5 correspond en général au hasard, un AUC de 1 serait un modèle parfait (qui ne fait jamais aucune erreur quelque soit le seuil).
")