Le perceptron multicouches
Le perceptron multicouches (Multi Layer Perceptron) généralise le perceptron afin d'apprendre des modèles plus complexes, non linéaires.
Un MLP est constitué :
-
d'une couche d'entrée (un neurone par variable plus un pour le biais)
-
une ou plusieurs couches cachées (avec un nombre arbitraire de neurones)
-
une couche de sortie (un neurone pour la regréssion ou la discrimination, un neurone par classe dans le multiclasse)
-
il est acyclique
-
il est complètement connecté
L'activation de chaque neurone se fait selon le calcul suivant :
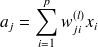 avec
avec
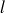 désignant la couche et
désignant la couche et
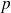 désignant le nombre de neurones de la couche précédente.
désignant le nombre de neurones de la couche précédente.
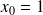 pour le biais.
pour le biais.
La fonction d'activation de chaque neurone est non linéaire :
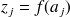 .
.
L'activation d'un neurone en sortie se fait selon le calcul suivant :
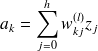 avec
avec
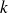 désignant le nombre de neurones de la couche de sortie et
désignant le nombre de neurones de la couche de sortie et
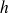 désignant le nombre de neurones de la couche précédente.
pour le biais.
désignant le nombre de neurones de la couche précédente.
pour le biais.
La fonction d'activation de chaque neurone est en général différente de celle des couches cachées :
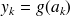 .
.
Exemple dans le cas d'un MLP à une seule couche cachée :
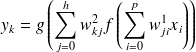
L'apprentissage d'un MLP passe par une technique d'optimisation de minimisation de l'erreur quadratique, telle que la descente de gradient, les gradients conjugués...
Toutefois, la technique la plus utilisée n'est pas une méthode d'apprentissage mais la rétro-propagation du gradient.
Principe : calculer l'erreur en sortie pour corriger le poids de la couche précédente, puis propager jusqu'à la couche d'entrée. La correction utlise la dérivée de l'erreur par rapport à chacun des poids de la couche précédente.

")