TP 1 de Data-Mining
Le but de ce TP est de mettre en oeuvre une méthode très simple de classification de données (les k plus proches voisins, ou knn) et de déterminer automatiquement le meilleur nombre de voisins à utiliser pour un problème donné. La validation de ce paramètre sera faite par validation croisée.
Contents
Les données
Il faut avoir un ensemble de données d'apprentissage (napp vecteurs de dimension d et étiquettes avec c classes) ainsi qu'un ensemble de test (ntest vecteurs de dimension d et étiquettes). Dans un premier temps, nous allons les générer de manière à obtenir des données sans erreurs puis nous utiliserons des données bruitées.
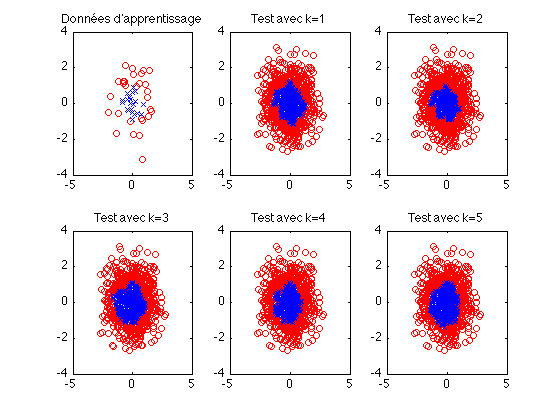
Problème 1 à deux classes
- les données d'apprentissage et de test sont tirées aléatoirement selon une loi normale centrée et réduite, en dimension d.
- les étiquettes sont calculées selon l'appartenance ou non du point à une boule de rayon R (ex: les point à l'intérieur de la boule sont étiquettés 1 et les autres 2.
Problème 2 à deux classes
- les caractéristiques sont identiques mais on introduit un bruit dans les données d'apprentissage : 5% des étiquettes sont échangées. On ne modifie pas les données de test.
kNN
- créer une fonction calculant le résultat dukNN telle que : function [etiquettesTest] = kNN(pointsApp,etiquettesApp, pointsTest, k)
- calculer l'erreur commise
- afficher les résultats
Validation de paramètres
- ecrire une fonction de validation croisée qui détermine la meilleure valeur de k pour chaque problème étudié.