Apprendre une catégorie d'images par classification à base de noyaux
Contents
Objectif
Le but de ce TP est d'utiliser les SVM en classification binaire pour faire de la reconnaissance de caractères (chiffres) et étudier la classification multiclasses.
Outils
- Les SVM utilisés sont ceux de la boîte à outils libSVM (disponible gratuitement en ligne).
- Les données sont issues de la base de données USPS (fournie avec le TP). Cette base de donnée contient des images représentant des chiffres manuscrits isolés sur des codes postaux. Cette base est utilisée classiquement pour l'évaluation des méthodes d'apprentissage.
Charger les données
clear all; close all; addpath('./Toolbox/libsvm-mat-2.88-1/'); load('usps.mat');
Observer la forme des données
whos
Transformer les données pour pouvoir les utiliser : on ne s'intéressera qu'aux classes 6 à 10 (pour des raisons de temps de calculs...)
A = find(train_labels>5); train_patterns = train_patterns(:,[A])'; train_labels = train_labels([A]); A = find(test_labels>5); test_patterns = test_patterns(:,[A])'; test_labels = test_labels([A]); whos
SVM Multiclasse
Mettre en oeuvre le SVM en version multiclasse "automatique" de libsvm, optimiser les paramètres à l'aide de la validation croisée.
Le multiclasse par défaut dans libSVM est le un contre un. Cela consiste à apprendre chaque couple de classes (1 contre 2, 1 contre 3, 2 contre 3, etc) puis de procéder à un vote majoritaire pour déterminer l'appartenance d'un exemple à l'une des classes. Ici, toute la procédure d'apprentissage des SVM binaire et le vote majoritaire sont pris en charge par la toolbox libSVM.
Pour information, l'autre méthode classique s'appele le un contre tous et consiste à regrouper dans un classe négative toutes les classes sauf une (qui sera la classe positive) et d'apprendre ainsi chaque classe contre les autres. Le choix de l'appartenance à une classe se fait alors selon la valeur max calculée par chacun des SVM binaires.
A vous de tester différentes plages de valeurs pour bandwidth et pour C. Celles données ici ne sont que des exemples.
bandwidth = [.01 0.02]; C = [10 20];
Lancement de la validation croisée (voir ici pour un exemple de code de validation croisée, dans une fonction à part.
nbFolders = 3; [I,J] = crossValidationClass(train_patterns,train_labels,nbFolders,C,bandwidth);
On récupère les meilleurs paramètres au sens de la validation croisée
bestKs = bandwidth(J(1)) bestCs = C(I(1))
On lance l'apprentissage final et le test sur les données d'apprentissage puis de test (connaitre l'erreur en apprentissage permet de se faire une idée du risque de sur-apprentissage.
param = ['-s 0 -c ', num2str(bestCs), ' -g ', num2str(bestKs)]; model = svmtrain(train_labels, train_patterns, param); [predict_label] = svmpredict(train_labels, train_patterns, model); [predict_label] = svmpredict(test_labels, test_patterns, model);
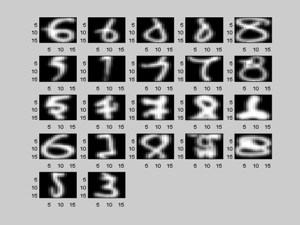
Affichage des images mal classées
A = find(predict_label~=test_labels); n = floor(sqrt(length(A)))+1; figure; for i=1:length(A) subplot(n,n,i); imagesc(reshape(test_patterns(A(i),:),16,16)'); colormap('gray'); end
Travail à réaliser
La partie à réaliser par vous même dans ce TP consiste à mettre un oeuvre une procédure d'apprentissage multiclasse plus précise que celle testée précédement. En effet, nous avons choisis un couple de paramètres optimaux avec la validation croisée, mais ils ne sont optimaux qu'en moyenne : rien ne permet de dire que les meilleurs paramètres pour l'apprentissage de la classe 2 contre 5 sont les mêmes que pour apprendre le duo 1 contre 8. Vous devez donc mettre en oeuvre une méthodologie permettant d'optimiser les paramètres de chaque SVM binaire puis combiner vos SVM afin d'obtenir une décision multiclasse. Pour faire ce travail, vous avez la possibilité de faire du un contre un (beaucoup de SVM de taille réduite et un vote majoritaire pour prendre la décision) ou du un contre tous (un SVM binaire par classe utilisant toutes les données à chaque fois puis un max sur prédictions de chaque SVM).
Sélection de la base pour un couple de classes : 2 contre 3
clear all; c1 = 2; c2 = 3; load('usps.mat'); A = find(train_labels==c1); B = find(train_labels==c2); trainvec = train_patterns(:,[A;B])'; trainlab = train_labels([A;B]); A = find(test_labels==c1); B = find(test_labels==c2); testvec = test_patterns(:,[A;B])'; testlab = test_labels([A;B]);