TP 3 Apprentissage : Réseaux de neurones
Contents
Objectifs
- coder un perceptron simple (décision linéaire)
- utiliser un perceptron multi-couche et apprécier l'influence des différents paramètres.
Préparation des données
Nous allons travailler sur 3 bases différentes. La première est un problème de classification binaire en 2D dans lequel les données sont séparables linéairement. La seconde sera un problème de classification bianire en 2D non séparable. La troisième sera un problème de classification binaire extrait de la base USPS, une des classes contre une des autres (cf. TP précédent). Pour chaque base, il faut générer la base d'apprentissage avec ses étiquettes ainsi que la base de test avec ses étiquettes.
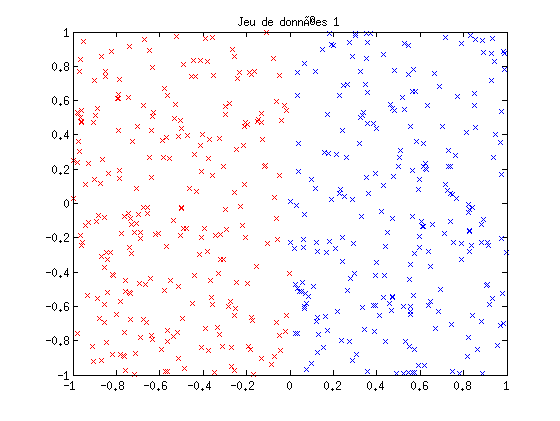
- Base 1 : les données sont des points 2D uniformément distribués sur [-1,1] dans chaque dimension. Les point dont l'abscisse est négative sont de la classe -1, les autres de la classe +1.
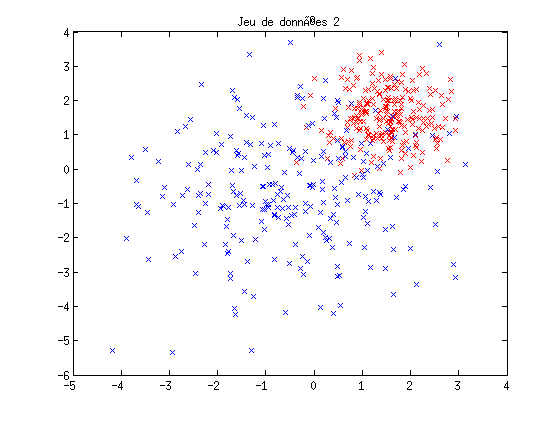
- Base 2 : les données sont générées à partir de deux distributions gaussiennes de centre et de variance différents, de façon à ce que les classes se chevauchent partiellement.
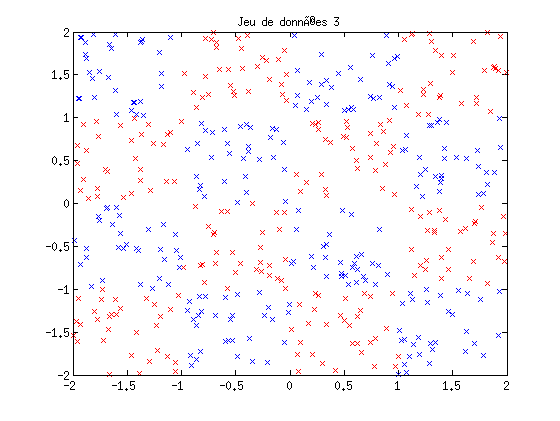
- Base 3 : les données représentent un damier
clear all; close all; napp = 500; ntest = 500; x1 = 2*rand(2,napp)-1; y1 = sign(x1(1,:)); xt1 = 2*rand(2,ntest)-1; yt1 = sign(xt1(1,:)); figure(1); plot(x1(1,y1==-1),x1(2,y1==-1),'rx'); hold on; plot(x1(1,y1==1),x1(2,y1==1),'bx'); title('Jeu de données 1'); x2 = [1.5*randn(2,round(napp/2))-0.5,0.7*randn(2,round(napp/2))+1.5]; y2 = [ones(1,round(napp/2)),-ones(1,round(napp/2))]; xt2 = [1.5*randn(2,round(ntest/2))-0.5,0.7*randn(2,round(ntest/2))+1.5]; yt2 = [ones(1,round(ntest/2)),-ones(1,round(ntest/2))]; figure(2); plot(x2(1,y2==-1),x2(2,y2==-1),'rx'); hold on; plot(x2(1,y2==1),x2(2,y2==1),'bx'); title('Jeu de données 2'); sigma = 0; % faire augmenter pour mélanger au frontières) nb=floor(napp/16); x3 = []; y3 = []; xt3 = []; yt3 = []; for i=-2:1; for j=-2:1; x3=[x3, [i+(1+sigma)*rand(1,nb);j+(1+sigma)*rand(1,nb)]]; y3=[y3, (2*rem((i+j+4),2)-1)*ones(1,nb)]; end; end; nb=floor(ntest/16); for i=-2:1; for j=-2:1; xt3=[xt3, [i+(1+sigma)*rand(1,nb);j+(1+sigma)*rand(1,nb)]]; %(2*rem((i+j+4),2)-1) yt3=[yt3, (2*rem((i+j+4),2)-1)*ones(1,nb)]; end; end; figure(3); plot(x3(1,y3==-1),x3(2,y3==-1),'rx'); hold on; plot(x3(1,y3==1),x3(2,y3==1),'bx'); title('Jeu de données 3');
Le perceptron
L'apprentissage d'un perceptron se fait selon la règle
w(t+1) = w(t) + eta*(y-yest)*x
où w est le vecteur de poids du perceptron, y l'étiquette (+1 ou -1), x est le point d'apprentissage courant,
yest = sign(x'*w(t))
l'étiquette estimée par le perceptron à l'instant t. Autrement dit, on ne met à jour le vecteur de poids w que lorsque l'exemple présenté est mal classé par le perceptron courant. eta est le taux d'apprentissage (compris entre 0 et 1).
- Ecrire une fonction qui calcule w en partant d'un vecteur aléatoire. L'apprentissage s'arrête soit lorsque tous les points d'apprentissage sont bien classés soit après un nombre maximum d'itérations.
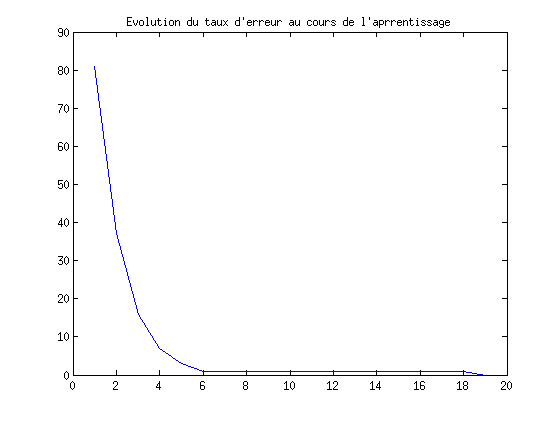
- Prévoir l'affichage de l'évolution de l'erreur au cours de l'apprentissage (après chaque passage complet de la base).
eta = 0.01; [w,suiviErr] = monPerceptron(x1,y1,eta);
Test du perceptron
- Utiliser la base 1 avec votre perceptron. Etudiez l'impact du paramètre eta sur la qualité de l'apprentissage.
- Utiliser les bases 2 et 3 avec votre perceptron. Conclure
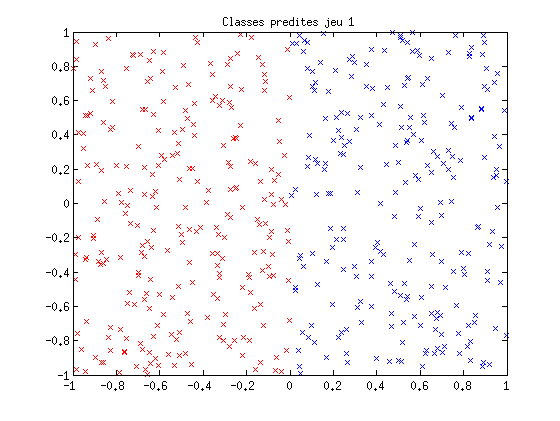
ypred = sign(w'*xt1); ErrorRate = 100*sum(abs(yt1-ypred))/(2*length(yt1)) figure(4); plot(suiviErr); title('Evolution du taux d''erreur au cours de l''aprrentissage'); figure(5); plot(xt1(1,ypred==-1),xt1(2,ypred==-1),'rx'); hold on; plot(xt1(1,ypred==1),xt1(2,ypred==1),'bx'); title('Classes predites jeu 1');
ErrorRate =
0
Le perceptron multi-couche (MLP)
La boite à outils netlab contient une implémentation d'un MLP. L'aide (help mpl) et les fichiers d'exemple demmplp1.m et demmpl2.m (dans le répertoire de la toolbox) vous permetrons d'apprendre l'utilisation de cette boîte à outils. Remarque : les sorties d'un MLP sont continues entre 0 et 1, il faut penser à les convertir en [-1,+1]...
- Utiliser les trois bases avec le MLP. Etudiez l'impact des paramètres sur la qualité de l'apprentissage (nombre de neurones cachés...). Faire varier le mélange dans les jeux de données.
- Conclure.
addpath('./Toolbox/netlab3.3/');
paramètres du MLP
nin = 2;
nhidden=3; % (à changer)
nout=1;
eta = 0.1;
construction du réseau (l'option 'linear' peut être changer en 'logistic' pour passer un non linéaire)
net = mlp(nin, nhidden, nout, 'linear', eta);
apprentissage du réseau en utilisant quasi-Newton.
options = zeros(1,18); options(1) = 1; % verbose options(14) = 10; % nb max cycles (à changer) [net] = netopt(net, options, x2', y2', 'quasinew');
Cycle 1 Function 210.494782 Cycle 2 Function 120.540908 Cycle 3 Function 106.714415 Cycle 4 Function 101.256881 Cycle 5 Function 101.158158 Cycle 6 Function 93.188993 Cycle 7 Function 92.378539 Cycle 8 Function 85.336511 Cycle 9 Function 77.856196 Cycle 10 Function 75.596479 Maximum number of iterations has been exceeded
test sur les données de test
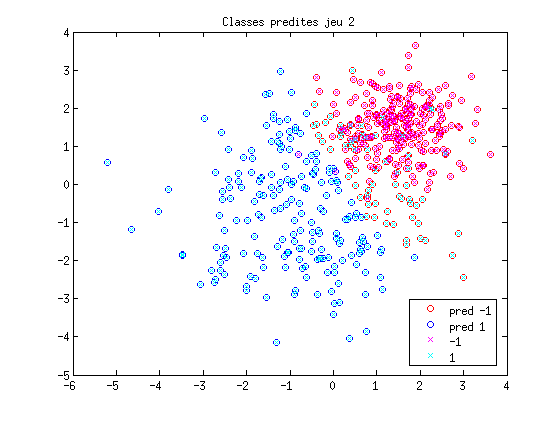
ypred = mlpfwd(net, xt2'); ypred = round(ypred); ypred(ypred==0) = -1; ErrorRate = 100*sum(abs(yt2-ypred'))/(2*length(yt2)) figure(6); plot(xt2(1,ypred==-1),xt2(2,ypred==-1),'ro'); hold on; plot(xt2(1,ypred==1),xt2(2,ypred==1),'bo'); plot(xt2(1,yt2==-1),xt2(2,yt2==-1),'mx'); plot(xt2(1,yt2==1),xt2(2,yt2==1),'cx'); title('Classes predites jeu 2'); legend('pred -1','pred 1', '-1','1',0);
ErrorRate = 13.4000